
I learned how to talk like a gen alpha
…and I did it at FAccT. Here’s what else happened

In June I went to the Fairness, Accountability, and Transparency conference in Athens, and then when I got back my psychologist forced me into a two-week moratorium on writing to ‘take the pressure off’ (what the hell does she know) in service of ‘protecting my mental stability’ (paraphrasing). Then I went on holiday. I’m back now.
I never usually go to conferences because as a freelancer it’s hard to know if they’re worth it: you might pay a lot of money to go to a bunch of lame keynotes and then not really meet anyone that you vibe with. Luckily a client paid for me to go to FAccT, and in return my colleague Soizic and I interviewed a bunch of people for two excellent podcast episodes: one on materiality & militarisation, the other on labour & misrepresentation.
Being at a conference like this as someone representing the Computer Says Maybe pod was kind of a double-edged sword. On the one hand, a lot of people knew about the show and told us how much they loved it. On the other hand, as a content and media person I felt like I stuck out like a sore thumb in what was broadly an academic space. Some academics — e.g. the snobby ones — struggle to relate to people who aren’t also academics, apparently lol. I didn’t spend much time hanging around with those folk because it was way too awkward.
The people I did choose to hang around with (e.g. the ones in the podcast) were excellent and I feel so privileged to have met them. I don’t want to talk about the contents of the interviews in heaps of detail here because you can, and should, just listen to the podcast episodes. Alongside making new friends, I also spent a lot of time becoming so dehydrated that I literally begun to dissociate — and when I wasn’t doing that, I went to paper presentations etc.
There were broadly two ways of thinking about AI at FAccT: one was that AI was already an unquestioned part of our reality, and we should use it for our benefit (eg to stop ableism or transphobia which in itself is kind of ironic) OR just try and improve it so it’s ’a bit less bad’ at whatever bad thing that particular researcher may have identified; and researchers so often get lost in their questions that they forget that problem-setting is kind of one of the most important part of finding a solution. Obviously I’m not an academic so what the hell do I know, but it did feel as though there was a real lack of critical thinking when it came to figuring out what problems are important, or indeed what things could even be characterised as problems. E.g. is it a problem that X AI-enabled system does not seem to treat Y marginalised group fairly? Or is the problem that the group is being forced to use a system they did not ask for?
The other tranche of thinking was to consider AI as an extractive, incapable, automator of hate and destroyer of workers’ rights — and therefore to actually criticise it. As someone totally rubbed raw by their own cynicism, I found this tranche much more engaging. But to start I want to highlight work from Myra Cheng, which wasn’t trying to solve a problem or tear down a system, but rather observe and understand people’s perceptions of AI. They surveyed 12k participants to provide open-ended metaphors for AI, and found twenty dominant metaphors ranging from ‘tool’ to ‘friend’ to ‘thief’. Then these sentiments were mapped onto a matrix that measured warmth on one axis, and competence on another:

The running theme through the dominant metaphors was anthropomorphisation: whether a dishonest incompetent thief, a wise helpful friend, or a dumb but reliable companion — these images are still skewed into human-like artefacts, as if AI is a kind of exercise in human-subtractive design: taking all the aspects that make up a human and removing a bunch of them to create something palatable, easy, robotic.
Also, ‘tool’ was the most mentioned metaphor, which makes sense, because it can contain so much nuance. A tool can help you write code. Equally, you can use something as a tool for emotional support; a tool that replicates a warm, safe conversation. I’m not saying that a chat bot is a good tool for this but many would disagree with me e.g. the people who feel they have lost a loved one since chatgpt got an update. Anyway, it would be interesting to examine what the dominant definitions were for ‘tool’.
Moving on to a presentation that both made me laugh and also feel deep horrifying shame for simply being an adult: Manisha Mehta, a literal 13-year-old girl who refuses to have a childhood, presented her evaluation on LLMs ‘understanding’ of Gen Alpha slang. She started with the below slide, asking if anyone in the audience understood any of it, before revealing the layperson definitions (most of us understood at least some!) and personally I think this entire research project has aura, fr fr.

Essentially moderation systems are developed by adults, some existed before these kids were even born, and therefore they absolutely do not recognise any of this language. Which means bullying and hate speech can fly under the radar. According to Manisha, slang changes so rapidly and/or is so context-dependant that it would be hard to keep up anyway: e.g. ‘bop’ is a derogatory word for women, and ‘let them cook’ could be good or bad depending on how you use it. It’s a fucking mess out there, basically, and current systems are not durable enough to handle this, quelle surprise.
A lot of researchers looked at problems like this and would build a solution around participatory design, inviting those most deeply effected by a problem to come in and help optimise/fix the systems that oppress them. A good example of this came from Francesca Lameiro who has worked on ways to detect transphobic speech online in order to give queer people the tools to avoid spaces that might make them feel unsafe. To do this, they scraped data from Tumblr, Truth Social, Youtube, and Reddit, and then brought in trans people to label data as either transphobic or not. Then, in a weird sort of anticlimax, Francesca announced that their main output for this work would be a Chrome extension.
I think there are a couple problems with this approach: firstly it’s a bit grim to ask trans people to do additional labour to address issues of hate speech that is directed at them — a thing they have to do all day every day anyway in their lives — especially when the labour is literally looking at transphobic content and then categorising it for an AI model. In her presentation, Francesca gave a couple of examples where data labellers struggled to decided whether a certain phrase could even count as transphobia — because of course they did, it would be impossible to be completely sure across all phrases. E.g. there are instances where uninformed people might ask good faith questions and use offensive speech due to negligence; or when someone is quoting someone else to make a point; or what about satirical speech?
The second problem with this approach is that bringing marginalised groups in to co-design a system that they never asked to be part of anyway, is not the same as fostering a strong, caring community. Trans misogyny online is a social problem that requires a social solution, not a technical one. I’m not sure how helpful it is creating a synthetic consensus around what is/isn’t transphobic and then setting it into a model that decides what is/isn’t safe on your behalf. This feels more like something that communities handle all on their own already: people talk to each other, offer advice, and learn what works for them. Operationalising this into a model kind of glazes over all the ways that communities support and care for each other.
Francesca’s work here is of course well-intentioned. There are other approaches, which might be framed as ‘participatory’, where researchers go into communities, draw on their expertise, and then use it to benefit the research, not the communities themselves — something that Teanna Barrett referred to as ‘parachute research’ in her presentation on African Data Ethics.
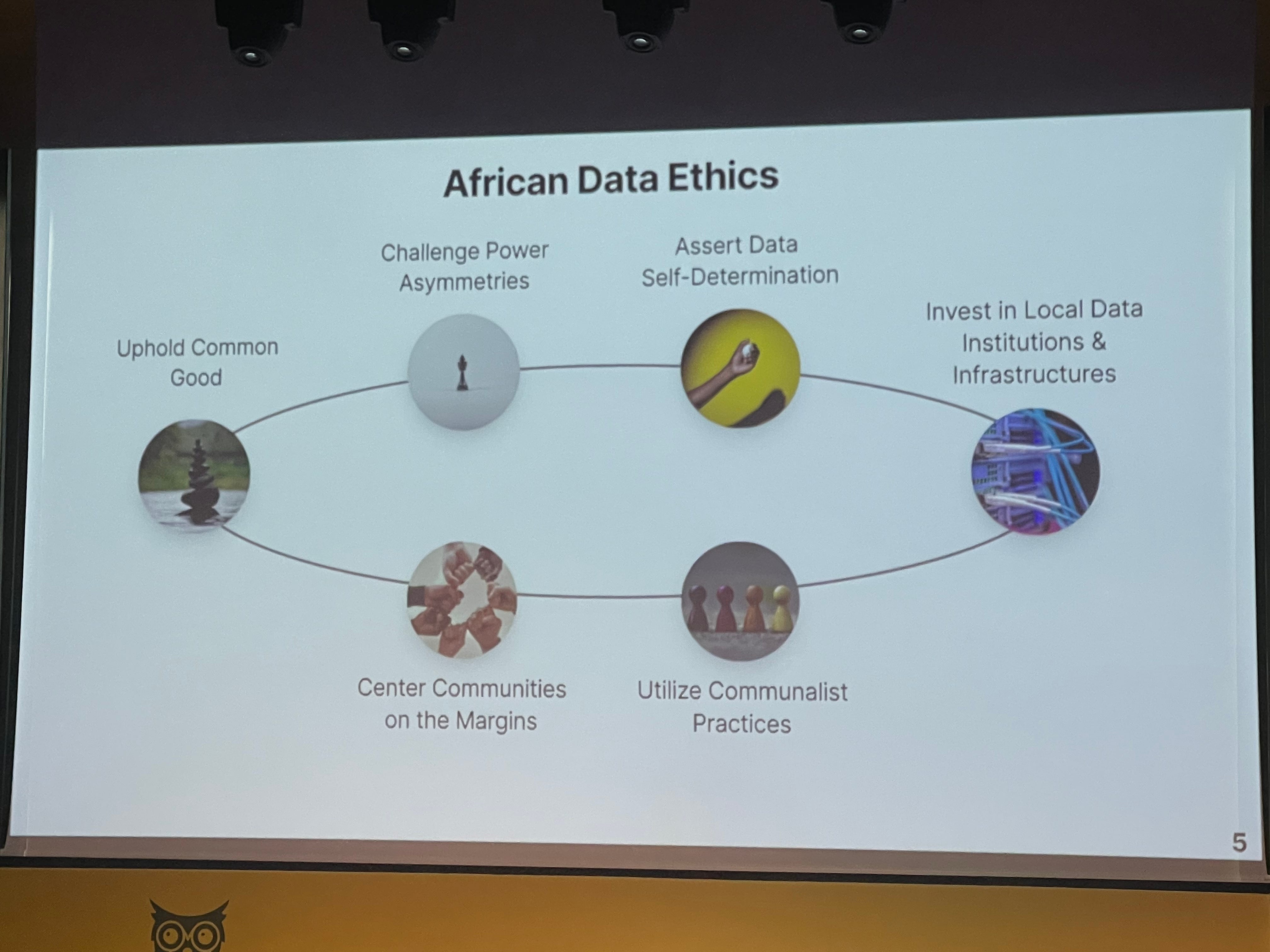
Something that stuck out to me here was her observation on how even in so-called ‘pluralistic’ fairness frameworks within responsible data science there are huge glaring omissions: African voices are often excluded, and African populations are just seen as this kind of raw cheap labour force for doing data work. What’s more, these frameworks will talk in vague terms about upholding a ‘common good’ within responsible data science, without discussing what that actually means in any depth — whereas African data ethics frameworks do. There’s a propensity for Western institutions to celebrate this fuzzy conception ‘social/common good’ without first thinking meaningfully about fixing what is broken: “African data ethics urges the RDS community to confront the harm they have caused before it can truly achieve social good.”
Then in Liberatory Collections and Ethical AI, Payton Croskey talked more specifically about data sets: Black communities are largely oppressed by how they are represented by these, so she surveyed fourteen ‘liberatory collections’ to understand more about data sets that gather information without being extractive, exploitative, or misrepresentative. The liberatory approach to data collection is about more than just avoiding harm to Black communities: it’s about valuing and preserving human information, and overall rethinking what a data set actually is. A liberatory collection is not restricted by the logics of absolute truths; it’s a living archive that changes and grows with culture, and is not design to be readable only by machines. With collections like these, you have to accept that they may not be the same years down the line, or even cease to exist.
It’s safe to say my note-taking apps have never been so brimming with concepts that I only half understand and want to read about more. I had a great time and if you were there, sorry I missed you!